
220 câu trắc nghiệm Cấu trúc dữ liệu và giải thuật có đáp án !!
Câu 1 :
Tìm mô tả đúng nhất cho hàm TinhTong sau:
int TinhTong(int N)
{ int so = 2; int tong = 0; int dem = 0; while (dem <N)
{
if (KiemTra(so) == 1)
{
tong = tong + so;
dem ++;
}
so = so + 1;
}
return tong;
} Trong đó
int KiemTra(int so)
{
for (int i = 2; i<so; i++)
if (so%i == 0)
return 0;
return 1;
}
int TinhTong(int N)
{ int so = 2; int tong = 0; int dem = 0; while (dem <N)
{
if (KiemTra(so) == 1)
{
tong = tong + so;
dem ++;
}
so = so + 1;
}
return tong;
} Trong đó
int KiemTra(int so)
{
for (int i = 2; i<so; i++)
if (so%i == 0)
return 0;
return 1;
}
A. Hàm tính tổng N số nguyên đầu tiên
B. Hàm tính tổng N số nguyên tố nhỏ hơn N
C. Cả a, b đều sai
Câu 2 :
Mối quan hệ giữa cấu trúc dữ liệu và giải thuật có thể minh họa bằng đẳng thức:
Câu 3 :
Các tiêu chuẩn đánh giá cấu trúc dữ liệu. Để đánh giá một cấu trúc dữ liệu chúng ta thường dựa vào một số tiêu chí:
Câu 4 :
Đoạn mã giả dưới đây mô tả thuật toán gì?
Thuật toán:
B1: k = 1
B2: IF M[k] == X AND k != N
B2.1: k++
B2.2: Lặp lại B2
B3: IF k < N Thông báo tìm thấy tại vị trí k
B4: ELSE Không tìm thấy.
B5: Kết thúc
Thuật toán:
B1: k = 1
B2: IF M[k] == X AND k != N
B2.1: k++
B2.2: Lặp lại B2
B3: IF k < N Thông báo tìm thấy tại vị trí k
B4: ELSE Không tìm thấy.
B5: Kết thúc
Câu 5 :
Cho hàm tìm kiếm tuyến tính như sau:
int TimKiem (int M[], int N, int X)
{ int k = 0;
M[N] = X;
while (M[k] != X)
k++;
if (k < N)
return (k);
return (-1);
}
Chọn câu đúng nhất:
Câu 6 :
Xét thủ tục sau:
int TimKiemNP (int M[], int First, int Last, int X)
{
if (First > Last)
return (-1);
int Mid = (First + Last)/2;
if (X == M[Mid])
return (Mid);
if (X < M[Mid])
return(TimKiemNP (M, First, Mid – 1, X));
else
return(TimKiemNP (M, Mid + 1, Last, X));
}
Lựa chọn câu đúng nhất để mô tả thủ tục trên:
int TimKiemNP (int M[], int First, int Last, int X)
{
if (First > Last)
return (-1);
int Mid = (First + Last)/2;
if (X == M[Mid])
return (Mid);
if (X < M[Mid])
return(TimKiemNP (M, First, Mid – 1, X));
else
return(TimKiemNP (M, Mid + 1, Last, X));
}
Lựa chọn câu đúng nhất để mô tả thủ tục trên:
Câu 7 :
Chọn câu đúng nhất để mô tả thuật toán sắp xếp nổi bọt (Bubble Sort) trên mảng M có N phần tử:
tử trồi lên đúng chỗ. Sau N–1 lần đi thì tất cả các phần tử trong mảng M sẽ có thứ tự tăng
Câu 8 :
Hàm mô tả sắp xếp nổi bọt (Bubble Sort) trên mảng M có N phần tử
void BubbleSort(int M[], int N)
{
[2] int Temp;
[3] for (int I = 0; I < N-1; I++)
[4] …………………………………..
[5] if (M[J] < M[J-1])
[6] {
[7] Temp = M[J];
[8] M[J] = M[J-1];
[9] M[J-1] = Temp;
[10] }
[11] return;
[12] }
[13]
Lệnh nào sau đây sẽ được đưa vào dòng lệnh thứ [5] của thủ tục:
void BubbleSort(int M[], int N)
{
[2] int Temp;
[3] for (int I = 0; I < N-1; I++)
[4] …………………………………..
[5] if (M[J] < M[J-1])
[6] {
[7] Temp = M[J];
[8] M[J] = M[J-1];
[9] M[J-1] = Temp;
[10] }
[11] return;
[12] }
[13]
Lệnh nào sau đây sẽ được đưa vào dòng lệnh thứ [5] của thủ tục:
Câu 9 :
Thủ tục mô tả thuật toán sắp xếp chọn trực tiếp (Straight Selection Sort):
void SapXepChonTrucTiep(T M[], int N)
{
int K = 0, PosMin;
int Temp;
while (K < N-1)
{ T Min = M[K];
PosMin = K;
for (int Pos = K+1; Pos < N; Pos++)
if (Min > M[Pos])
{
Min = M[Pos];
PosMin = Pos
}
} ...................................
[1] ...................................
[2] ...................................
[3] K++;
}
return;
}
Chọn câu lệnh thích hợp để đưa vào [1], [2], [3] với mục tiêu hoán vị M[K] và M[PosMin]
void SapXepChonTrucTiep(T M[], int N)
{
int K = 0, PosMin;
int Temp;
while (K < N-1)
{ T Min = M[K];
PosMin = K;
for (int Pos = K+1; Pos < N; Pos++)
if (Min > M[Pos])
{
Min = M[Pos];
PosMin = Pos
}
} ...................................
[1] ...................................
[2] ...................................
[3] K++;
}
return;
}
Chọn câu lệnh thích hợp để đưa vào [1], [2], [3] với mục tiêu hoán vị M[K] và M[PosMin]
Câu 10 :
Đối với thuật toán sắp xếp chọn trực tiếp cho dãy các phần tử sau (10 pt) 16 60 2 25 15 45 5 30 33 20
Cần thực hiện ..................... chọn lựa phần tử nhỏ nhất để sắp xếp mảng M có thứ tự tăng dần.
Cần thực hiện ..................... chọn lựa phần tử nhỏ nhất để sắp xếp mảng M có thứ tự tăng dần.
Câu 11 :
Thuật toán sắp xếp chèn trực tiếp (Straight Insertion Sort) được mô tả bằng đoạn mã giả như sau:
B1: K = 1
B2: IF (K = N) Thực hiện BKT
B3: X = M[K+1]
B4: Pos = 1
B5: IF (Pos > K) Thực hiện B7
B6: ELSE // Tìm vị trí chèn
B6.1: If (X <= M[Pos]) Thực hiện B7
B6.2: Pos++
B6.3: Lặp lại B6.1
B7: I = K+1 B8: IF (I > Pos)
B8.1: M[I] = M[I-1]
B8.2: I--
B8.3: Lặp lại B8
B9: ELSE
B9.1: M[Pos] = X
B9.2: K++
B9.3: Lặp lại B2
BKT: Kết thúc Trong đó B8 mô tả trường hợp
B1: K = 1
B2: IF (K = N) Thực hiện BKT
B3: X = M[K+1]
B4: Pos = 1
B5: IF (Pos > K) Thực hiện B7
B6: ELSE // Tìm vị trí chèn
B6.1: If (X <= M[Pos]) Thực hiện B7
B6.2: Pos++
B6.3: Lặp lại B6.1
B7: I = K+1 B8: IF (I > Pos)
B8.1: M[I] = M[I-1]
B8.2: I--
B8.3: Lặp lại B8
B9: ELSE
B9.1: M[Pos] = X
B9.2: K++
B9.3: Lặp lại B2
BKT: Kết thúc Trong đó B8 mô tả trường hợp
Câu 12 :
Giả sử cần sắp xếp mảng M có N phần tử sau theo phương pháp sắp xếp chèn trực tiếp 11 16 12 75 51 54 5 73 36 52 98
Cần thực hiện ..................... chèn các phần tử vào dãy con đã có thứ tự tăng đứng đầu dãy M để sắp xếp mảng M có thứ tự tăng dần.
Cần thực hiện ..................... chèn các phần tử vào dãy con đã có thứ tự tăng đứng đầu dãy M để sắp xếp mảng M có thứ tự tăng dần.
Câu 13 :
Lựa chọn định nghĩa về danh sách đúng nhất?
A. Danh sách là tập hợp các phần tử có kiểu dữ liệu xác định và giữa
chúng có một mối liên hệ nào đó
B. Số phần tử của danh sách gọi là chiều dài của danh sách
C. Một danh sách có chiều dài bằng 0 là một danh sách rỗng
Câu 14 :
Tìm mô tả đúng cho hàm sau:
int SC (int M[], int Len, int CM[])
{ for (int i = 0; i < Len; i++)
CM[i] = M[i];
return (Len);
}
int SC (int M[], int Len, int CM[])
{ for (int i = 0; i < Len; i++)
CM[i] = M[i];
return (Len);
}
A. Hàm thực hiện việc sao chép nội dung mảng CM có chiều dài Len về
mảng M có cùng chiều dài. Hàm trả về chiều dài của mảng M sau khi sao
chép
B. Hàm thực hiện việc sao chép nội dung mảng M có chiều dài Len -1 về
mảng CM có cùng chiều dài. Hàm trả về chiều dài của mảng CM sau khi
sao chép
C. Hàm thực hiện việc sao chép nội dung mảng CM có chiều dài Len -1 về
mảng M có cùng chiều dài. Hàm trả về chiều dài của mảng M sau khi sao
chép
mảng CM có cùng chiều dài. Hàm trả về chiều dài của mảng CM sau khi
sao chép
Câu 15 :
Cấu trúc dữ liệu mảng có các ưu điểm nào?
A. Việc thêm, bớt các phần tử trong danh sách đặc có nhiều khó khăn do
phải di dời các phần tử khác đi qua chỗ khác
B. Việc truy xuất và tìm kiếm các phần tử của mảng là dễ dàng vì các phần
tử đứng liền nhau nên chúng ta chỉ cần sử dụng chỉ số để định vị vị trí các
phần tử trong danh sách (định vị địa chỉ các phần tử)
C. Mật độ sử dụng bộ nhớ của mảng là tối ưu tuyệt đối
Câu 16 :
Định nghĩa nào là đúng với danh sách liên kết?
A. Danh sách liên kết là cấu trúc dữ liệu dạng cây
B. Danh sách liên kết là cấu trúc dữ liệu tự định nghĩa
C. Danh sách liên kết là tập hợp các phần tử mà giữa chúng có một sự nối
kết với nhau thông qua vùng liên kết của chúng
vùng nhớ
Câu 17 :
Định nghĩa cấu trúc dữ liệu của danh sách liên kết đơn được mô tả như sau:
typedef struct Node
{ int Key;
Node * NextNode;
} OneNode;
Trong đó, khai báo Node * NextNode; dùng để mô tả:
typedef struct Node
{ int Key;
Node * NextNode;
} OneNode;
Trong đó, khai báo Node * NextNode; dùng để mô tả:
A. Con trỏ trỏ tới phần dữ liệu
B. Vùng liên kết quản lý địa chỉ phần tử kế tiếp
C. Con trỏ trỏ tới địa chỉ vùng nhớ của phần tử trước đó trong danh sách
liên kết đơn
liên kết đơn
Câu 18 :
Với cấu trúc dữ liệu của danh sách liên kết đơn lưu trữ thông tin về phòng máy:
typedef struct PM
{
int maPM; int tongsoMay;
} PHONGMAY;
typedef struct Node { PHONGMAY Data; Node * NextNode;
} OneNode;
typedef OneNode * SLLPointer;
Để quản lý danh sách liên kết đơn bằng phần tử đầu và phần tử cuối, cần định nghĩa kiểu dữ liệu:
typedef struct PM
{
int maPM; int tongsoMay;
} PHONGMAY;
typedef struct Node { PHONGMAY Data; Node * NextNode;
} OneNode;
typedef OneNode * SLLPointer;
Để quản lý danh sách liên kết đơn bằng phần tử đầu và phần tử cuối, cần định nghĩa kiểu dữ liệu:
A. SLLPointer DanhSach;
B. typedef struct SSLLIST { SLLPointer First; SLLPointer Last; } LIST; LIST DanhSach;
C. typedef struct SSLLIST { SLLPointer First; SLLPointer Last; int total; }LIST; LIST DanhSach;
Câu 19 :
Tổ chức cấu trúc dữ liệu cho danh sách liên kết đơn:
typedef struct Node
{ int Data; Node * Link;
} OneNode; typedef OneNode * SLLPointer;
Mã giả thuật toán thêm một phần tử có giá trị thành phần dữ liệu là NewData vào trong danh sách liên kết đơn SLList vào ngay sau nút có
địa chỉ InsNode:
B1: NewNode = new OneNode
B2: IF (NewNode = NULL) Thực hiện BKT
B3: NewNode ->Link = NULL
B4: NewNode ->Data = NewData
B5: IF (InsNode-> Link = NULL)
B5.1: InsNode-> Link = NewNode
B5.2: Thực hiện BKT // Nối các nút kế sau InsNode vào sau NewNode
B6: ………………………………………………..
// Chuyển mối liên kết giữa InsNode với nút kế của nó về NewNode
B7: ………………………………………………..
BKT: Kết thúc
B6 và B7 dùng để nối nút kế sau InsNode vào sau NewNode và chuyển mối liên kết giữa InsNode với nút kế nó về NewNode.
Hãy chọn câu đúng nhất cho B6 và B7
typedef struct Node
{ int Data; Node * Link;
} OneNode; typedef OneNode * SLLPointer;
Mã giả thuật toán thêm một phần tử có giá trị thành phần dữ liệu là NewData vào trong danh sách liên kết đơn SLList vào ngay sau nút có
địa chỉ InsNode:
B1: NewNode = new OneNode
B2: IF (NewNode = NULL) Thực hiện BKT
B3: NewNode ->Link = NULL
B4: NewNode ->Data = NewData
B5: IF (InsNode-> Link = NULL)
B5.1: InsNode-> Link = NewNode
B5.2: Thực hiện BKT // Nối các nút kế sau InsNode vào sau NewNode
B6: ………………………………………………..
// Chuyển mối liên kết giữa InsNode với nút kế của nó về NewNode
B7: ………………………………………………..
BKT: Kết thúc
B6 và B7 dùng để nối nút kế sau InsNode vào sau NewNode và chuyển mối liên kết giữa InsNode với nút kế nó về NewNode.
Hãy chọn câu đúng nhất cho B6 và B7
A. B6: InsNode-> Link = NewNode-> Link B7: NewNode = InsNode-> Link
B. B6: InsNode-> Link = NewNode-> Link B7: InsNode-> Link = NewNode
C. B6: NewNode-> Link = InsNode-> Link B7: NewNode = InsNode-> Link
Câu 20 :
Với định nghĩa cấu trúc dữ liệu cho danh sách liên kết đơn:
typedef struct Node
{
int Data; Node * Link;
} OneNode;
typedef OneNode * SLLPointer;
Hàm dưới đây để thêm một phần tử có giá trị thành phần dữ liệu là NewData vào trong danh sách liên kết đơn SLList vào ngay sau nút có địa chỉ InsNode.
SLLPointer ThemGiua(SLLPointer &SList, int NewData, SLLPointer &InsNode)
{ SLLPointer NewNode = new OneNode;
if (NewNode != NULL)
NewNode ->NextNode = NULL;
NewNode ->Data = NewData;
else
return (NULL);
if (InsNode->Link == NULL)
{
InsNode-> Link = NewNode; return (SList);
}
…………………………………………………………….
…………………………………………………………….
return (SList);
}
Hãy lựa chọn câu đúng nhất:
typedef struct Node
{
int Data; Node * Link;
} OneNode;
typedef OneNode * SLLPointer;
Hàm dưới đây để thêm một phần tử có giá trị thành phần dữ liệu là NewData vào trong danh sách liên kết đơn SLList vào ngay sau nút có địa chỉ InsNode.
SLLPointer ThemGiua(SLLPointer &SList, int NewData, SLLPointer &InsNode)
{ SLLPointer NewNode = new OneNode;
if (NewNode != NULL)
NewNode ->NextNode = NULL;
NewNode ->Data = NewData;
else
return (NULL);
if (InsNode->Link == NULL)
{
InsNode-> Link = NewNode; return (SList);
}
…………………………………………………………….
…………………………………………………………….
return (SList);
}
Hãy lựa chọn câu đúng nhất:
A. InsNode -> Link = NewNode -> Link; InsNode-> Link = NewNode;
B. NewNode-> Link = InsNode-> Link; InsNode-> Link = NewNode;
C. InsNode -> Link = NewNode -> Link; NewNode = InsNode-> Link;
Câu 21 :
Cấu trúc dữ liệu nào tương ứng với LIFO?
A. Queue
B. Linked List
C. Tree
Câu 22 :
Lựa chọn câu đúng nhất về danh sách liên kết đôi (Doubly Linked List):
A. Vùng liên kết của một phần tử trong danh sách liên đôi có 02 mối liên kết với 01 phần tử khác trong danh sách
B. Vùng liên kết của một phần tử trong danh sách liên đôi có 01 mối liên kết với 02 phần tử khác trong danh sách
C. Vùng liên kết của một phần tử trong danh sách liên đôi có 02 mối liên kết với 02 trước và sau nó trong danh sách
Câu 23 :
Cho thuật toán tìm nhị phân không đệ quy sau:
int NRecBinarySearch (int M[], int N, int X)
{ int First = 0;
int Last = N – 1;
while (First <= Last)
{
int Mid = (First + Last)/2;
if (X == M[Mid])
return(Mid);
if (X < M[Mid])
Last = Mid – 1;
else
First = Mid + 1;
}
return(-1);
}
Chọn câu đúng nhất trong trường hợp tốt nhất khi phần tử ở giữa của mảng có giá trị bằng X:
int NRecBinarySearch (int M[], int N, int X)
{ int First = 0;
int Last = N – 1;
while (First <= Last)
{
int Mid = (First + Last)/2;
if (X == M[Mid])
return(Mid);
if (X < M[Mid])
Last = Mid – 1;
else
First = Mid + 1;
}
return(-1);
}
Chọn câu đúng nhất trong trường hợp tốt nhất khi phần tử ở giữa của mảng có giá trị bằng X:
A. Số phép gán: Gmin = 3 Số phép so sánh: Smin = 2
B. Số phép gán: Gmin = 2 Số phép so sánh: Smin = 3
C. Số phép gán: Gmin = 2 Số phép so sánh: Smin = 2
Câu 24 :
Cho thuật toán sắp xếp Bubble Sort như sau:
void BubbleSort(int M[], int N)
{
for (int I = 0; I < N-1; I++)
for (int J = N-1; J > I; J--)
if (M[J] < M[J-1])
Swap(M[J], M[J-1]);
return;
}
Chọn câu đúng nhất cho hàm Swap
void BubbleSort(int M[], int N)
{
for (int I = 0; I < N-1; I++)
for (int J = N-1; J > I; J--)
if (M[J] < M[J-1])
Swap(M[J], M[J-1]);
return;
}
Chọn câu đúng nhất cho hàm Swap
A. void Swap(int &X, int &Y) { int Temp = X; X = Y; Y = Temp; return; }
B. void Swap(float X, floatY) { int Temp = X; X = Y; Y = Temp; return; }
C. void Swap(int *X, int *Y) { int Temp = X; X = Y; Y = Temp; return; }
Câu 25 :
Cho cây biểu thức sau:
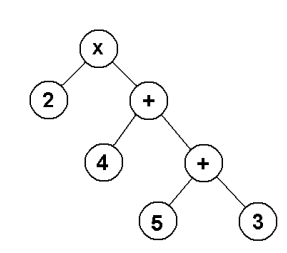
Chọn biểu thức tương ứng với cây
Chọn biểu thức tương ứng với cây
A. (2 * (4 + (5 + 3)))
B. (4 * (2+ (5 + 3)))
C. (2 * (3 + (5 +4)))
Câu 26 :
Cho thuật toán sau:
int LinearSearch (int M[], int N, int X)
{ int k = 0;
while (M[k] != X k < N )
k++;
if (k < N )
return (k);
return (-1);
}
Chọn câu đúng nhất trong trường hợp xấu nhất khi không tìm thấy phần tử nào có giá trị bằng X:
int LinearSearch (int M[], int N, int X)
{ int k = 0;
while (M[k] != X k < N )
k++;
if (k < N )
return (k);
return (-1);
}
Chọn câu đúng nhất trong trường hợp xấu nhất khi không tìm thấy phần tử nào có giá trị bằng X:
A. Số phép gán: Gmax = 1 Số phép so sánh: Smax = 2N+1
B. Số phép gán: Gmax = 2 Số phép so sánh: Smax = 2N+1
C. Số phép gán: Gmax = 1 Số phép so sánh: Smax = 2N+2
Câu 27 :
Cho thuật toán sau:
int LinearSearch (float M[], int N, float X)
{
int k = 0;
M[N] = X;
while (M[k] != X) //n+1 lan
(M[k] != X) //n+1 lan k++;
if (k < N)
return (k);
return (-1);
}
Chọn câu đúng nhất trong trường hợp xấu nhất khi không tìm thấy phần tử nào có giá trị bằng X:
int LinearSearch (float M[], int N, float X)
{
int k = 0;
M[N] = X;
while (M[k] != X) //n+1 lan
(M[k] != X) //n+1 lan k++;
if (k < N)
return (k);
return (-1);
}
Chọn câu đúng nhất trong trường hợp xấu nhất khi không tìm thấy phần tử nào có giá trị bằng X:
A. Số phép gán: Gmax = 1 Số phép so sánh: Smax = N + 2
B. Số phép gán: Gmax = 2 Số phép so sánh: Smax = N + 2
C. Số phép gán: Gmax = 2 Số phép so sánh: Smax = N + 1
Câu 28 :
Cấu trúc dữ liệu cho kiểu dữ liệu sinh viên như sau:
typedef struct tagSV{
char MSSV[8];
char Ten[30];
char NgaySinh[11];
float DTB;
}SV;
Khai báo
SV sv1, *sv2;
Lựa chọn các câu đúng nhất để gán giá trị cho mã sinh viên của sv1 và sv2:
typedef struct tagSV{
char MSSV[8];
char Ten[30];
char NgaySinh[11];
float DTB;
}SV;
Khai báo
SV sv1, *sv2;
Lựa chọn các câu đúng nhất để gán giá trị cho mã sinh viên của sv1 và sv2:
A. sv1.MSSV = “Nguyen Van A”; sv2.MSSV = “Nguyen Van B”;
B. sv1.MSSV = “Nguyen Van A”; sv2->MSSV = “Nguyen Van B”;
C. sv1->MSSV = “Nguyen Van A”; sv2->MSSV = “Nguyen Van B”;
Câu 29 :
Với thủ tục như sau:
void operation()
{
int x,a[10],n;
int x,m,l,h,flag=0;
cout<<"Enter the element to be searched:";
cin>>x;
l=0; h=n-1;
while(l<=h)
{
m=(l+h)/2;
if(x==a[m]) {
lag=1; break;
}
else if(x>a[m])
l=m+1;
else if(x<a[m])
h=m-1;
}
if(flag==0)
cout<<"ABSENT";
else
cout<<"PRESENT";
}
Lựa chọn câu đúng nhất để mô tả thủ tục trên
void operation()
{
int x,a[10],n;
int x,m,l,h,flag=0;
cout<<"Enter the element to be searched:";
cin>>x;
l=0; h=n-1;
while(l<=h)
{
m=(l+h)/2;
if(x==a[m]) {
lag=1; break;
}
else if(x>a[m])
l=m+1;
else if(x<a[m])
h=m-1;
}
if(flag==0)
cout<<"ABSENT";
else
cout<<"PRESENT";
}
Lựa chọn câu đúng nhất để mô tả thủ tục trên
A. Thủ tục tìm nhị phân phần tử được nhập từ bàn phím, nếu tìm thấy sẽ thông báo ABSENT
B. Thủ tục tìm nhị phân phần tử được nhập từ bàn phím, nếu không tìm thấy sẽ thông báo ABSENT
C. Thủ tục tìm tuyến tính phần tử được nhập từ bàn phím, nếu tìm thấy sẽ thông báo ABSENT
Câu 30 :
Biểu diễn và tổ chức ngăn xếp (Stack) bằng danh sách liên kết giả sử bề mặt của ngăn xếp là đầu danh sách liên kết:
typedef struct SElement
{ T Key;
SElement *Next;
} SOneElement;
typedef struct SOneElement *SSTACK;
SSTACK SSP;
Thêm 1 phần tử vào ngăn xếp (dùng cấu trúc dữ liệu mô tả ở trên)
B1: NewElement = Khởi tạo nút mới (dùng toán tử new)
B2: if (NewElement == NULL)
Thực hiện BKT
B3: if (SSP == NULL)
B3.1: SSP = NewElement
B3.2: Thực hiện BKT
B4: …………………………………………
B5: …………………………………………
BKT: Kết thúc
Chọn câu lệnh chính xác cho B4 và B5
typedef struct SElement
{ T Key;
SElement *Next;
} SOneElement;
typedef struct SOneElement *SSTACK;
SSTACK SSP;
Thêm 1 phần tử vào ngăn xếp (dùng cấu trúc dữ liệu mô tả ở trên)
B1: NewElement = Khởi tạo nút mới (dùng toán tử new)
B2: if (NewElement == NULL)
Thực hiện BKT
B3: if (SSP == NULL)
B3.1: SSP = NewElement
B3.2: Thực hiện BKT
B4: …………………………………………
B5: …………………………………………
BKT: Kết thúc
Chọn câu lệnh chính xác cho B4 và B5
A. B4: NewElement ->Next = SSP SSP = NewElement
B. B4: SSP = NewElement ->Next B5: SSP = NewElement
C. B4: SSP = NewElement ->Next B5: NewElement = SSP
Câu 31 :
Cấu trúc dữ liệu biểu diễn hàng đợi bằng danh sách liên kết:
typedef struct QElement
{ T Key;
QElement *Next;
} QOneElement;
typedef QElement *QType;
Cấu trúc dữ liệu quản lý hàng đợi bằng hai phần tử đầu (Front) và cuối
(Rear):
typedef struct QPElement
{ QType Font;
QType Rear;
} SQUEUE;
SQUEUE SQList;
Thêm phần tử vào sau phần tử Rear. Giả sử dữ liệu đưa vào hàng đợi là NewData, mã giả được mô tả như sau:
B1: NewElement = Khởi tạo nút mới có thành phần NewData
B2: IF (NewElement == NULL)
Thực hiện BKT
B3: IF (SQList.Front == NULL) // hàng đợi dang rỗng
B3.1: SQList.Front = SQList.Rear = NewElement
B3.2: Thực hiện BKT
B4: …………………………………………..
B5: …………………………………………..
BKT: Kết thúc
Chọn câu đúng nhất cho bước B4, B5
typedef struct QElement
{ T Key;
QElement *Next;
} QOneElement;
typedef QElement *QType;
Cấu trúc dữ liệu quản lý hàng đợi bằng hai phần tử đầu (Front) và cuối
(Rear):
typedef struct QPElement
{ QType Font;
QType Rear;
} SQUEUE;
SQUEUE SQList;
Thêm phần tử vào sau phần tử Rear. Giả sử dữ liệu đưa vào hàng đợi là NewData, mã giả được mô tả như sau:
B1: NewElement = Khởi tạo nút mới có thành phần NewData
B2: IF (NewElement == NULL)
Thực hiện BKT
B3: IF (SQList.Front == NULL) // hàng đợi dang rỗng
B3.1: SQList.Front = SQList.Rear = NewElement
B3.2: Thực hiện BKT
B4: …………………………………………..
B5: …………………………………………..
BKT: Kết thúc
Chọn câu đúng nhất cho bước B4, B5
A. B4: SQList.Front->Next = NewElement B5: SQList.Front = NewElement
B. B4: SQList.Rear->Next = NewElement B5: SQList.Rear = NewElement
C. B4: NewElement = SQList.Rear->Next B5: SQList.Rear = NewElement
Câu 32 :
Chọn định nghĩa đúng nhất về hàng đợi (Queue):
A. Hàng đợi còn được gọi là danh sách FILO và cấu trúc dữ liệu này còn được gọi cấu trúc FILO (First In Last Out)
B. Hàng đợi là một danh sách mà trong đó thao tác thêm 1 phần tử vào trong danh sách được thực hiện 1 đầu này và lấy 1 phần tử trong danh sách lại thực hiện bởi đầu kia
C. Hàng đợi là một danh sách mà trong đó thao tác thêm 1 phần tử hay hủy một phần tử trong danh sách được thực hiện 1 đầu
Câu 33 :
Chiều dài đường đi của một cây (path’s length of the tree) được định nghĩa là tổng tất cả các chiều dài đường đi của tất cả các nút trên cây. Xét cây sau:
A. Chiều dài đường của cây trên là 63
B. Chiều dài đường của cây trên là 64
C. Chiều dài đường của cây trên là 65
Câu 34 :
Chọn định nghĩa đúng nhất đối với cây nhị phân tìm kiếm:
A. Cây nhị phân tìm kiếm là cây nhị phân có thành phần khóa của mọi nút lớn hơn thành phần khóa của tất cả các nút trong cây con trái của nó và nhỏ hơn thành phần khóa của tất cả các nút trong cây con phải của nó
B. Cây nhị phân tìm kiếm là cây nhị phân có thành phần khóa của mọi nút nhỏ hơn thành phần khóa của tất cả các nút trong cây con trái của nó và nhỏ hơn thành phần khóa của tất cả các nút trong cây con phải của nó
C. Cây nhị phân tìm kiếm là cây nhị phân có thành phần khóa của mọi nút lớn hơn thành phần khóa của tất cả các nút trong cây con trái của nó và lớn hơn thành phần khóa của tất cả các nút trong cây con phải của nó.
Câu 35 :
Chọn định nghĩa đúng nhất về cây cân bằng tương đối:
A. Cây cân bằng tương đối là một cây nhị phân thỏa mãn điều kiện là đối với mọi nút của cây thì số nút của cây con trái và số nút của cây con phải của nút đó hơn kém nhau không quá 1. Cây cân bằng tương đối còn được
gọi là cây AVL (AVL tree)
B. Cây cân bằng tương đối là một cây N phân thỏa mãn điều kiện là đối với mọi nút của cây thì chiều cao của cây con trái và chiều cao của cây con phải của nút đó hơn kém nhau không quá 2. Cây cân bằng tương đối còn
được gọi là cây AVL (AVL tree)
C. Cây cân bằng tương đối là một cây nhị phân thỏa mãn điều kiện là đối với mọi nút của cây thì chiều cao của cây con trái và chiều cao của cây con phải của nút đó hơn kém nhau không quá 1. Cây cân bằng tương đối còn
được gọi là cây AVL (AVL tree)
Câu 36 :
Định nghĩa cấu trúc dữ liệu của danh sách liên kết đơn được mô tả như sau:
struct Node
{
int Key; Node *
NextNode;
} OneNode;
Trong đó, khai báo Node * NextNode; dùng để mô tả
struct Node
{
int Key; Node *
NextNode;
} OneNode;
Trong đó, khai báo Node * NextNode; dùng để mô tả
A. Con trỏ trỏ tới phần dữ liệu
B. Vùng liên kết quản lý địa chỉ phần tử kế tiếp
C. Con trỏ trỏ tới phần dữ liệu cuối của danh sách
Câu 37 :
Khi cần thêm một phần tử có giá trị thành phần dữ liệu là NewData (là một số nguyên) vào đầu của danh sách liên kết đơn dùng thuật toán có mã giả mô tả như dưới đây?
typedef struct Node
{
int Data; Node * NextNode;
} OneNode; typedef OneNode * SLLPointer;
SLLPointer SSList;
B1: NewNode = new OneNode
B2: IF (NewNode = NULL) Thực hiện BKT
B3: NewNode ->NextNode = NULL
B4: NewNode ->Data = NewData B5: NewNode->NextNode = SLList
B6: SLList = NewNode BKT: Kết thúc
Tìm mô tả chính xác cho B5
typedef struct Node
{
int Data; Node * NextNode;
} OneNode; typedef OneNode * SLLPointer;
SLLPointer SSList;
B1: NewNode = new OneNode
B2: IF (NewNode = NULL) Thực hiện BKT
B3: NewNode ->NextNode = NULL
B4: NewNode ->Data = NewData B5: NewNode->NextNode = SLList
B6: SLList = NewNode BKT: Kết thúc
Tìm mô tả chính xác cho B5
A. Chuyển vai trò đứng đầu của NewNode cho SLList
B. Nối NewNode vào sau SLList
C. Chuyển vai trò đứng đầu của SLList cho NewNode
Câu 38 :
Tìm kiếm xem trong danh sách liên kết đơn có tồn tại nút có thành phần dữ liệu là SearchData hay không. Thao tác này chúng ta vận dụng thuật toán tìm tuyến tính để tìm kiếm:
typedef struct Node
{
int Data;
Node * Link;
} OneNode;'
typedef OneNode * Pointer;
Pointer SSList; // Quản lý danh sách liên kết đơn bởi 1 phần tử đầu
B1: CurNode = SLList
B2: IF (………………………………………………)
Thực hiện BKT
B3: CurNode = CurNode->Link
B4: Lặp lại B2
BKT: Kết thúc
Chọn điều kiện hợp lý cho mã giả ở B2
typedef struct Node
{
int Data;
Node * Link;
} OneNode;'
typedef OneNode * Pointer;
Pointer SSList; // Quản lý danh sách liên kết đơn bởi 1 phần tử đầu
B1: CurNode = SLList
B2: IF (………………………………………………)
Thực hiện BKT
B3: CurNode = CurNode->Link
B4: Lặp lại B2
BKT: Kết thúc
Chọn điều kiện hợp lý cho mã giả ở B2
A. CurNode != NULL OR CurNode->Data = SearchData
B. CurNode = NULL OR CurNode->Data != SearchData
C. CurNode = NULL OR CurNode->Data = SearchData
Câu 39 :
Cho cấu trúc dữ liệu như sau:
typedef struct Node
{
int Key;
Node *NextNode;
} OneNode;
typedef SLLOneNode * Type;
Thuật toán chọn trực tiếp viết trên ngôn ngữ C++ áp dụng cho danh sách liên kết đơn quản lý bởi một phần tử đầu tiên được mô tả:
void StraightSelection(Type &SList)
{
Type MinNode;
int Temp;
Type CurrNode,TempNode;
CurrNode = SList;
while (CurrNode!=NULL)
{
TempNode = CurrNode->NextNode;
MinNode = CurrNode;
while (TempNode!=NULL)
{
TempNode = CurrNode->NextNode;
MinNode = CurrNode;
while (TempNode!=NULL)
{
if (………………………………………………)
MinNode = TempNode;
TempNode = TempNode->NextNode;
}
[1] Temp = MinNode->Key;
[2] MinNode->Key = CurrNode->Key;
[3] CurrNode->Key = Temp CurrNode=CurrNode->NextNode;
}
}
Tìm mô tả chính xác cho [1], [2], [3]
typedef struct Node
{
int Key;
Node *NextNode;
} OneNode;
typedef SLLOneNode * Type;
Thuật toán chọn trực tiếp viết trên ngôn ngữ C++ áp dụng cho danh sách liên kết đơn quản lý bởi một phần tử đầu tiên được mô tả:
void StraightSelection(Type &SList)
{
Type MinNode;
int Temp;
Type CurrNode,TempNode;
CurrNode = SList;
while (CurrNode!=NULL)
{
TempNode = CurrNode->NextNode;
MinNode = CurrNode;
while (TempNode!=NULL)
{
TempNode = CurrNode->NextNode;
MinNode = CurrNode;
while (TempNode!=NULL)
{
if (………………………………………………)
MinNode = TempNode;
TempNode = TempNode->NextNode;
}
[1] Temp = MinNode->Key;
[2] MinNode->Key = CurrNode->Key;
[3] CurrNode->Key = Temp CurrNode=CurrNode->NextNode;
}
}
Tìm mô tả chính xác cho [1], [2], [3]
A. Hoán vị 2 mối liên kết
B. Hoán vị 2 vùng giá trị
C. Hoán vị nút đầu và nút cuối
Câu 40 :
Với cấu trúc dữ liệu như sau:
typedef struct DNode
{
int Key;
DNode * NextNode;
DNode * PreNode;
} DOneNode
typedef DLLOneNode * DPointerType;
typedef struct DPairNode
{ DPointerType DLLFirst;
DPointerType DLLLast;
} DPType;
Hàm thêm phần tử vào cuối danh sách liên kết đôi quản lý bởi 2 phần
tử đầu và cuối
DPointerType DLLAddLast(DPType &DList, int NewData)
{
DPointerType NewNode = gọi hàm tạo nút mới có vùng dữ liệu là
NewData ;
if (NewNode == NULL)
return (NULL);
if (DList.DLLLast == NULL)
DList.DLLFirst = DList.DLLLast = NewNode;
else
{
……………………………………………….
……………………………………………….
………………………………………………
}
return (NewNode);
} Hãy lựa chọn câu đúng nhất để điền vào chỗ trống ở trên
typedef struct DNode
{
int Key;
DNode * NextNode;
DNode * PreNode;
} DOneNode
typedef DLLOneNode * DPointerType;
typedef struct DPairNode
{ DPointerType DLLFirst;
DPointerType DLLLast;
} DPType;
Hàm thêm phần tử vào cuối danh sách liên kết đôi quản lý bởi 2 phần
tử đầu và cuối
DPointerType DLLAddLast(DPType &DList, int NewData)
{
DPointerType NewNode = gọi hàm tạo nút mới có vùng dữ liệu là
NewData ;
if (NewNode == NULL)
return (NULL);
if (DList.DLLLast == NULL)
DList.DLLFirst = DList.DLLLast = NewNode;
else
{
……………………………………………….
……………………………………………….
………………………………………………
}
return (NewNode);
} Hãy lựa chọn câu đúng nhất để điền vào chỗ trống ở trên
A. DList.DLLLast ->NextNode = NewNode; NewNode ->PreNode = DList.DLLLast; NewNode = DList.DLLLast;
B. DList.DLLLast ->NextNode = NewNode; DList.DLLLast = NewNode ->PreNode; DList.DLLLast = NewNode;
C. NewNode = DList.DLLLast ->NextNode; NewNode ->PreNode = DList.DLLLast; DList.DLLLast = NewNode;
Câu 41 :
Với cấu trúc dữ liệu như sau:
typedef struct DNode
{
int Key;
DNode * NextNode;
DNode * PreNode;
} DOneNode;
typedef DOneNode * DPointerType;
typedef struct DLLPairNode
{ DPointerType DLLFirst;
DPointerType DLLLast;
} DLLPType;
Hàm duyệt qua các nút trong danh sách liên kết đôi quản lý bởi hai địa chỉ nút đầu tiên và nút cuối cùng thông qua DList để xem nội dung thành phần dữ liệu của mỗi nút
void DLLTravelling (DLLPType DList)
{
DPointerType CurrNode = DList.DLLFirst;
while (CurrNode != NULL) { cout <<
CurrNode->Key; …………………………………
}
return;
}
Chọn câu chính xác điền vào chỗ trống để mô tả việc di chuyển từ nút này sang nút khác
typedef struct DNode
{
DNode * NextNode;
DNode * PreNode;
} DOneNode;
typedef DOneNode * DPointerType;
typedef struct DLLPairNode
{ DPointerType DLLFirst;
DPointerType DLLLast;
} DLLPType;
Hàm duyệt qua các nút trong danh sách liên kết đôi quản lý bởi hai địa chỉ nút đầu tiên và nút cuối cùng thông qua DList để xem nội dung thành phần dữ liệu của mỗi nút
void DLLTravelling (DLLPType DList)
{
DPointerType CurrNode = DList.DLLFirst;
while (CurrNode != NULL) { cout <<
CurrNode->Key; …………………………………
}
return;
}
Chọn câu chính xác điền vào chỗ trống để mô tả việc di chuyển từ nút này sang nút khác
A. CurrNode = CurrNode ->NextNode ;
B. CurrNode = CurrNode ->Key ;
C. CurrNode ->NextNode = CurrNode;
Câu 42 :
Với cấu trúc dữ liệu mô tả cho Stack:
typedef struct SElement
{
int Key;
SElement *Next;
} SOneElement;
typedef SOneElement *SSTACK;
Tìm mô tả chính xác cho hàm sau:
void SSDelete (SSTACK &SList)
{
while (SList != NULL)
{ SSTACK TempElement = SList;
SList = SList ->Next;
TempElement ->Next = NULL;
delete TempElement;
}
}
typedef struct SElement
{
int Key;
SElement *Next;
} SOneElement;
typedef SOneElement *SSTACK;
Tìm mô tả chính xác cho hàm sau:
void SSDelete (SSTACK &SList)
{
while (SList != NULL)
{ SSTACK TempElement = SList;
SList = SList ->Next;
TempElement ->Next = NULL;
delete TempElement;
}
}
A. Hủy phần tử đầu của Stack
B. Hủy phần tử cuối của Stack
C. Hủy phần tử cuối của Stack và lấy giá trị đó in ra màn hình
Câu 43 :
Kết quả nào đúng khi thực hiện giải thuật sau:
long lt(int n)
{if (n==0) return 1;
else return (2*lt(n-1);
}
long lt(int n)
{if (n==0) return 1;
else return (2*lt(n-1);
}
A. lt(12) = 2010
B. lt(12) = 1024
C. lt(7) = 720
Câu 44 :
Kết quả nào đúng khi thực hiện giải thuật sau với a[]= {1, 3, 5}; n= 5, k= 3:
![Kết quả nào đúng khi thực hiện giải thuật sau với a[]= {1, 3, 5}; n= 5, k= 3: (ảnh 1)](https://video.vietjack.com/upload2/quiz_source1/2022/07/capture-3-1657803431.png)
A. 2 3 4
B. 1 2 3
C. 2 3 5
Câu 45 :
Kết quả nào đúng khi thực hiện giải thuật sau với a[]= {-3, -3, 15, -3}; n= 4; x= -3:
int FindX(int a[], int n, int x)
{int i;
for (i= n; i>= 1; i--) if (a[i]==x) return (i);
return (-1);
}
int FindX(int a[], int n, int x)
{int i;
for (i= n; i>= 1; i--) if (a[i]==x) return (i);
return (-1);
}
A. 1
B. 2
C. 3
Câu 46 :
Dấu hiệu nào dưới đây cho biết danh sách liên kết đơn L là rỗng:
A. (L->left == NULL)
B. (L->ìnfor == NULL)
C. (L->next == NULL)
Câu 47 :
Kết quả nào đúng khi thực hiện giải thuật sau với a[]= {1, 3, 5, 4, 2}; n= 5:
![Kết quả nào đúng khi thực hiện giải thuật sau với a[]= {1, 3, 5, 4, 2}; n= 5: (ảnh 1)](https://video.vietjack.com/upload2/quiz_source1/2022/07/capture-4-1657803764.png)
A. 1 4 2 3 5
B. 5 4 3 2 1
C. 1 4 5 3 2
Câu 48 :
Thao tác nào dưới đây thực hiện trên hàng đợi (queue):
A. Thêm phần tử vào lối sau
B. Loại bỏ phần tử ở lối sau
C. Thêm phần tử vào lối trước
Câu 49 :
Dấu hiệu nào dưới đây cho biết hàng đợi đã có thao tác thêm và loại bỏ phần tử là rỗng:
A. Lối trước có giá trị > giá trị của lối sau
B. Lối sau nhận giá trị = 0
C. Lối trước có giá trị < giá trị của lối sau
Câu 50 :
Thao tác nào dưới đây thực hiện trên ngăn xếp (stack):
A. Thêm phần tử vào vị trí bất kỳ
B. Loại bỏ phần tử tại vị trí bất kỳ
C. Thêm và loại bỏ phần tử luôn thực hiện tại vị trí đỉnh (top)
Câu 51 :
Trong phép duyệt cây nhị phân có 24 nút theo thứ tự sau, nút gốc có thứ tự:
A. Thứ 1
B. Thứ 2
C. Thứ 23
Câu 52 :
Nút có khóa nhỏ nhất trong cây nhị phân tìm kiếm khác rỗng là:
A. Nút gốc
B. Tất cả các nút
C. Nút con bên phải nhất
Câu 53 :
Cây nhị phân khác rỗng là cây:
A. Mỗi nút (trừ nút lá) đều có hai nút con
B. Tất cả các nút đều có nút con
C. Mỗi nút có không quá 2 nút con
Câu 54 :
Đồ thị G có n đỉnh và m cạnh với m, n thì ma trận kề của G luôn có dạng:
A. là ma trận vuông cấp n
B. là ma trận cấp nxm
C. là ma trận vuông cấp m
Câu 55 :
Đồ thị vô hướng G có chu trình Euler khi và chỉ khi:
A. G liên thông và mọi đỉnh G có bậc chẵn
B. mọi đỉnh G có bậc chẵn
C. G có chu trình Hamilton
Câu 56 :
Nhân tố nào là nhân tố chính ảnh hưởng đến thời gian tính của một giải thuật:
A. Máy tính
B. Thuật toán được sử dụng
C. Chương trình dịch
Câu 57 :
Chọn phát biểu đúng trong các phát biểu dưới đây: bằng cách chạy thử 1 thuật toán với 1 bộ dữ liệu, ta có thể:
A. Khẳng định thuật toán đúng nếu nó cho kết quả đúng
B. Khẳng định thuật toán sai nếu cho kết quả sai
C. Khẳng định thuật toán tốt nếu cho kết quả nhanh
Câu 58 :
Trong các mệnh đề sau đây, mệnh đề nào sai:
A. Kiểu dữ liệu là một tập hợp nào đó các phần tử dữ liệu cùng chung một thuộc tính
B. kiểu của một ngôn ngữ bao gồm các kiểu dữ liệu đơn và các phương pháp cho phép ta từ các kiểu dữ liệu đã có xây dựng nên các kiểu dữ liệu mới
C. Cấu trúc dữ liệu là các dữ liệu phức tạp, được xây dựng nên từ các kiểu dữ liệu đã có, đơn giản hơn bằng các phương pháp liên kết nào đó
Câu 59 :
Tìm mệnh đề sai trong các mệnh đề sau: Một cấu trúc dữ liệu bao gồm…
Câu 60 : Cho danh sách đặc có 10 phần tử. Khi thêm phần tử vào vị trí 4 trong danh sách, vòng lặp dịch chuyển tịnh tiến nội dung các phần tử L->Elements[i]=L->Elements[i+1] sẽ thực hiện:
A. 4 lần
B. 5 lần
C. 6 lần
Câu 61 :
Cho danh sách đặc có 10 phần tử. Khi xóa phần tử ở vị trí 4 trong danh sách, vòng lặp dịch chuyển tịnh tiến nội dung các phần tử L->Elements[i]=L->Elements[i+1] :
A. 4 lần
B. 5 lần
C. 6 lần
Câu 62 :
Cho biểu thức a+b*((c-d)*e+f/h). Danh sách duyệt tiền tự của biểu thức
đã cho là:
đã cho là:
A. + * a b + * - c d e / f h
B. + a * b + * - c d e / f h
C. + a b * * e - c d + / f h
Câu 63 :
Danh sách duyệt hậu tự của biểu thức trong câu 3 là:
A. a c d - * e b * + f h / +
B. a b c d - e * + f h / * +
C. a b c d - e * f h / + * +
Câu 64 :
Danh sách duyệt theo mức của biểu thức đã cho trong câu 3 là:
A. + a * b + * / - e f h c d
B. a b + * + / - c d e f h *
C. + * a + b – c d * e / f h
Câu 65 :
Trong các phát biểu sau, phát biểu nào đúng?
A. Giá trị hàm EndList(L) và hàm FirstList(L) luôn luôn bằng nhau khi danh sách rỗng
B. Giá trị hàm EndList(L) và hàm FirstList(L) luôn luôn khác nhau
C. Giá trị hàm EndList(L) và hàm FirstList(L) bằng nhau hay không tùythuộc vào phương pháp cài đặt danh sách
Câu 66 :
Giải thuật là … câu lệnh chặt chẽ, rõ ràng và xác định một trình tự các thao tác trên các đối tượng dữ liệu
A. một
B. hai
Câu 67 :
Sau một số … bước thực hiện giải thuật cho chúng ta đạt được kết quả mong muốn:
A. vô hạn
B. giới hạn
C. hữu hạn
Câu 68 :
Đánh giá độ phức tạp của giải thuật là việc xác định … và … mà giải thuật cần để thực hiện giải một bài toán:
A. Khoảng thời gian, độ khó
B. Khoảng thời gian, độ khó
C. Khoảng thời gian, dung lượng bộ nhớ máy tính
Câu 69 :
Các kiểu dữ liệu cơ bản là:
A. các kiểu dữ liệu mà người lập trình được cung cấp sẵn từ máy tính
B. các kiểu dữ liệu mà người lập trình được cung cấp sẵn từ ngôn ngữ tự nhiên
C. các kiểu dữ liệu mà người lập trình được cung cấp sẵn từ ngôn ngữ lập trình
Câu 70 :
Chỉ ra kiểu dữ liệu cơ bản:
A. Sinh viên
B. Float
C. Họtên
Câu 71 :
Chỉ ra kiểu dữ liệu không cơ bản:
A. Char
B. int
C. long
Câu 72 :
Kiểu dữ liệu trừu tượng là …
A. Kiểu dữ liệu mà người lập trình phải tự xây dựng không dựa trên các kiểu dữ liệu cơ bản được cung cấp từ ngôn ngữ lập trình
B. Kiểu dữ liệu mà người lập trình phải tự xây dựng dựa trên các kiểu dữ liệu không cơ bản được cung cấp từ ngôn ngữ lập trình
C. Kiểu dữ liệu mà người lập trình phải tự xây dựng dựa trên các kiểu dữ liệu cơ bản được cung cấp từ ngôn ngữ máy
Câu 73 :
Chỉ ra kiểu dữ liệu trừu tượng:
A. float
B. int
C. char
Câu 74 :
Cấu trúc dữ liệu là …
A. cách lưu trữ dữ liệu trong bộ nhớ máy tính (ROM), sao cho nó có thể được sử dụng một cách hiệu quả
B. cách lưu trữ dữ liệu trong bộ nhớ máy tính (HDD), sao cho nó có thể được sử dụng một cách hiệu quả
C. cách lưu trữ dữ liệu trong bộ nhớ máy tính (USB), sao cho nó có thể được sử dụng một cách hiệu quả
Câu 75 :
Mối quan hệ giữa cấu trúc dữ liệu và giải thuật có thể minh hoạ bằng đẳng thức:
A. Chương trình = Cấu trúc dữ liệu
B. Giải thuật + Chương trình = Cấu trúc dữ liệu
C. Cấu trúc dữ liệu + Chương trình = Giải thuật
Câu 76 :
Phát biểu sau đúng hay sai: Khi cấu trúc dữ liệu thay đổi thì giải thuật cũng thay đổi theo?
Câu 77 :
Phát biểu sau đúng hay sai: khi nói tới dữ liệu thì cũng phải xem xét dữ liệu đó cần được thực hiện bằng giải thuật gì để đạt được kết quả mong muốn?
A. Đúng
Câu 78 :
Phát biểu sau đúng hay sai: Khi nói tới giải thuật phải xem xét nó sẽ tác động trên dữ liệu nào?
A. Đúng
B.Sai
Câu 79 :
Phát biểu sau đúng hay sai: Giải thuật thể hiện hành động của các bước để giải bài toán?
A. Đúng
B. Sai
Câu 80 :
Phát biểu sau đúng hay sai: Dữ liệu là đối tượng được xử lý , nó biểu diễn các thông tin cần thiết cho bài toán: dữ liệu vào, dữ liệu ra?
A. Đúng
B.Sai
Câu 81 :
Chỉ ra khái niệm có tính chất đệ quy?
A. khái niệm tính giai thừa của n (n!)
B. khái niệm hình ảnh
Câu 82 :
Phát biểu sau đúng hay sai: Trong lập trình, giải thuật đệ quy được sử dụng để xây dựng hàm đệ quy?
A. Đúng
Câu 83 :
Phát biểu sau đúng hay sai: Hàm đệ quy là hàm mà trong thân hàm có lời gọi hàm đến chính nó?
A. Đúng
B. Sai
Câu 84 :
Phát biểu sau đúng hay sai: Chương trình đệ quy là những chương trình máy tính có sử dụng giải thuật đệ quy?
A. Đúng
B. Sai
Câu 85 :
Phát biểu sau đúng hay sai: Khi có lời gọi đệ quy, trạng thái hiện thời của chương trình (giá trị hiện thời của các biến, điểm ngắt thực hiện của chương trình) được lưu vào vùng bộ nhớ ngăn xếp?
A. Đúng
B. Sai
Câu 86 :
Phát biểu sau đúng hay sai: Khi hết lời gọi đệ quy, chương trình chưa kết thúc. Chương trình được tiếp tục thực hiện từ "điểm ngắt" với những giá trị của các biến ở thời điểm ngắt?
A. Đúng
B. Sai
Câu 87 :
Cho bài toán: cho trước n là một số tự nhiên, tính n!. Chỉ ra trường hợp suy biến
A. với n = 0
B. với n = 1
Câu 88 :
Hãy chọn định nghĩa đúng nhất về danh sách kiểu hàng đợi (Queue)?
A. Hàng đợi là kiểu danh sách tuyến tính trong đó, phép bổ sung một phần tử được thực hiện ở một đầu, gọi là lối sau (rear) hay lối trước (front). Phép loại bỏ không thực hiện được
B. Hàng đợi là kiểu danh sách tuyến tính trong đó, phép bổ sung một phần tử hay loại bỏ được thực hiện ở một đầu danh sách gọi là đỉnh (Top)
C. Hàng đợi là một danh sách tuyến tính trong đó phép bổ sung một phần tử và phép loại bỏ một phần tử được thực hiện ở tại một vị trí bất kì trong danh sách
Câu 89 :
Trong bốn kiểu ký hiệu sau đây, ký hiệu nào biểu thị cho danh sách kiểu hàng đợi?
A. FIFO
B. LIFO
C. FILO
Câu 90 :
Để thêm một đối tượng x bất kỳ vào Stack, ta dùng hàm nào sau đây?
A. TOP(x)
B. EMPTY(x)
C. PUSH(x)
Câu 91 :
Để loại bỏ một đối tượng ra khỏi Stack, ta dùng hàm nào sau đây?
A. FULL(x)
B. POP(x)
C. EMPTY(x)
Câu 92 :
Trong lưu trữ dữ liệu kiểu Queue (Q) dưới dạng mảng nối vòng, giả sử F là con trỏ trỏ tới lối trước của Q, R là con trỏ trỏ tới lối sau của Q. Điều kiện F=R=0 nghĩa là gì trong các phương án sau?
A. Queue tràn
B. Queue rỗng
C. Kiểm tra chỉ số trước và chỉ số sau của Queue có bằng nhau hay không
Câu 93 :
Trong lưu trữ dữ liệu kiểu Queue (Q), giả sử F là con trỏ trỏ tới lối trước của Q, R là con trỏ trỏ tới lối sau của Q. Khi thêm một phần tử vào Queue, thì R và F thay đổi thế nào trong các phương án sau?
A. F không thay đổi, R=R+1
B. F=F+1, R không thay đổi
C. F không thay đổi, R=R-1
Câu 94 :
Trong lưu trữ dữ liệu kiểu Queue (Q), giả sử F là con trỏ trỏ tới lối trước của Q, R là con trỏ trỏ tới lối sau của Q. Khi loại bỏ một phần tử vào Queue, thì R và F thay đổi thế nào trong các phương án sau?
A. F=F+1, R không thay đổi
B. F không thay đổi, R=R+1
C. F không thay đổi, R=R-1
Câu 95 :
Cho cây nhị phân: A, B, C, D, E, F, G, H, I, J, K, L, M, N. Cây con trái của
cây B bao gồm những phần tử nào trong các phương án sau?
cây B bao gồm những phần tử nào trong các phương án sau?
A. E, J, K
B. C, D
C. C, D, E
Câu 96 :
Cho cây nhị phân: A, B, C, D, E, F, G, H, I, J, K, L, M, N. Cây con trái của cây C bao gồm những phần tử nào trong các phương án sau?
A. E, F, G
B. F, L, M
C. E, F
Câu 97 :
Cho cây nhị phân: A, B, C, D, E, F, G, H, I, J, K, L, M, N. Cây con phải của cây C bao gồm những phần tử nào trong các lựa chọn sau?
A. D, E
B. F, G, L
C. D, E, F
Câu 98 :
Cho cây nhị phân: A, B, C, D, E, F, G, H, I, J, K, L, M, N. Cây con phải của cây B bao gồm những phần tử nào trong các lựa chọn sau?
A. E,K
B. C, D
C. E, J, K
Câu 99 :
Hãy cho biết quy tắc đúng của phép duyệt cây theo thứ tự trước trong các phương án sau?
A. Duyệt cây con trái theo thứ tự trước; Duyệt cây con phải theo thứ tự trước; Duyệt gốc
B. Duyệt gốc; Duyệt cây con trái theo thứ tự trước; Duyệt cây con phải theo thứ tự trước
C. Duyệt gốc, cây trái, cây phải đồng thời theo thứ tự trước
Câu 100 :
Hãy cho biết quy tắc đúng của phép duyệt cây theo thứ tự giữa trong các phương án sau?
A. Duyệt gốc, cây trái, cây phải đồng thời theo thứ tự giữa
B. Duyệt gốc; Duyệt cây con trái theo thứ tự giữa; Duyệt cây con phải theo thứ tự giữa
C. Duyệt cây con trái theo thứ tự giữa; Duyệt cây con phải theo thứ tự giữa; Duyệt gốc
Câu 101 :
Hãy cho biết quy tắc đúng của phép duyệt cây theo thứ tự sau trong các phương án sau?
A. Duyệt cây con trái theo thứ tự sau; Duyệt gốc; Duyệt cây con phải theo thứ tự sau
B. Duyệt gốc, cây trái, cây phải đồng thời theo thứ tự sau
C. Duyệt cây con trái theo thứ tự sau; Duyệt cây con phải theo thứ tự sau; Duyệt gốc
Câu 102 :
Yếu tố nào sau đây để xây dựng nên một chương trình hoàn chỉnh?
A. Dữ liệu tốt, giải thuật đơn giản
B. Giải thuật có thời gian thực hiện nhanh nhất
C. Cấu trúc dữ liệu thích hợp, giải thuật xử lý hiệu quả
Câu 103 :
Theo các phương án dưới đây, kích thước lưu trữ kiểu số nguyên (Integer) bao nhiêu byte?
A. 1 byte
B. 2 byte
C. 4 byte
Câu 104 :
Hãy chọn Câu trả lời đúng nhất về giải thuật?
A. Giải thuật hay còn gọi là thuật toán dùng để chỉ phương pháp hay cách thức giải quyết vấn đề( bao gồm một dãy các bước tính toán rõ ràng và chính xác)
B. Giải thuật là nòng cốt của chương trình
C. Giải thuật là một dãy hữu hạn các bước, tất cả các phép toán có mặt trong các bước của thuật toán phải đủ đơn giản
Câu 105 :
Hãy cho biết đâu là đặc trưng của thuật toán trong các phương án sau?
A. Mỗi thuật toán có bộ dữ liệu vào, ra tương ứng
B. Mỗi bước của thuật toán cần phải được mô tả một các chính xác
C. Thuật toán phải dừng lại sau một số hữu hạn các bước cần thực hiện
Câu 106 :
Dựa vào yếu tố nào sau đây để đánh giá thời gian thực hiện của giải thuật?
A. Thời gian khi chạy chương trình cụ thể
B. Tính xác định
C. Độ phức tạp tính toán của giải thuật
Câu 107 :
Hãy cho biết phương án đúng của để sắp xếp theo thứ tự tăng dần của cấp thời gian thực hiện chương trình?
A. O(1), O(logn), O(n), O(nlogn)
B. O(1), O(nlogn), O(n), O(logn)
C. O(logn), O(n), O(nlogn), O(1)
Câu 108 :
Hãy cho biết Câu trả lời đúng nhất về đặc điểm của giải thuật đệ quy?
A. Trong thủ tục đệ quy có lời gọi đến chính thủ tục đó
B. Sau mỗi lần có lời gọi đệ quy thì kích thước của bài toán được thu nhỏ hơn trước
C. Có một trường hợp đặc biệt, trường hợp suy biến. Khi trường hợp này xảy ra thì bài toán còn lại sẽ được giải quyết theo một cách khác
Câu 109 :
Hãy cho biết phương pháp nào sau đây để loại bỏ nút X trên cây nhị phân tìm kiếm, với X là một phần tử bất kỳ?
A. Chỉ việc xoá X, vì X không liên quan đến phần tử nào khác
B. Tìm nút chứa khoá lớn nhất trong cây con trái, đưa giá trị chứa trong đó sang nút X , rồi xoá X
C. Không thể xoá X ra khỏi cây nhị phân tìm kiếm
Câu 110 :
Với dữ liệu đầu vào (n) đủ nhỏ, ta nên sử dụng phương pháp sắp xếp nào sau đây?
A. Sắp xếp nhanh(quick sort)
B. Sắp xếp vun đống(Heap sort)
C. Sắp xếp lựa chọn(selection sort)
Câu 111 :
Trong các danh sách tuyến tính sau đây, danh sách nào sau đây có dạng ngăn xếp?
A. Là một danh sách tuyến tính trong đó phép bổ sung một phần tử vào ngăn xếp và phép loại bỏ một phần tử khỏi ngăn xếp luôn luôn thực hiện ở một đầu gọi là đỉnh
B. Là một danh sách tuyến tính trong đó phép bổ sung sung một phần tử vào ngăn xếp được thực hiện ở một đầu, Và phép loại bỏ không thực hiện được
C. Là một danh sách tuyến tính trong đó phép bổ sung một phần tử vào ngăn xếp và phép loại bỏ một phần tử khỏi ngăn xếp luôn luôn thực hiện ở tại một vị trí bất kì trong danh sách
Câu 112 :
Danh sách tuyến tính dạng ngăn xếp làm việc theo nguyên tắc nào sau đây?
A. LILO(last in last out)
B. LIFO(last in first out)
C. FIFO( first in first out)
Câu 113 :
Với dữ liệu đầu vào (n) lớn, ta nên sử dụng phương pháp sắp xếp nào sau đây?
A. Sắp xếp trộn (Merge sort) hoặc Sắp xếp đống(Heap sort)
B. Sắp xếp đống(Heap sort) hoặc Sắp xếp nhanh(quick sort)
C. Sắp xếp chọn(selection sort), sắp xếp chèn ( Insert sort)
Câu 114 :
Hãy cho biết phát biểu nào đúng nhất về Giải thuật đệ quy?
A. Trong giải thuật của nó có lời gọi tới một giải thuật khác đã biết kết quả
B. Trong giải thuật của nó có lời gọi tới chính nó nhưng với phạm vi lớn hơn
C. Trong giải thuật của nó có lời gọi tới chính nó nhưng với phạm vi nhỏ hơn
Câu 115 :
Giả sử T1(n) và T2(n) là thời gian thực hiện của hai giai đoạn chương trình P1 và P2 mà T1(n) = O(f(n)); T2(n) = O(g(n)). Theo qui tắc tổng xác định độ phức tạp tính toán của giải thuật thì thời gian thực hiện đoạn P1 rồi đến P2 là phương án nào sau đây?
A. T1(n) + T2(n) = O(Min(f(n),g(n)))
B. T1(n) + T2(n) = O(max(f(n),g(n)))
C. T1(n) + T2(n) = O((f(n) or g(n)))
Câu 116 :
Trong một chương trình có 3 bước thực hiện, mà thời gian thực hiện từng bước lần lượt là O(n^2), O(n^3) và O(nlogn). Cho biết thời gian thực hiện của chương trình là bao nhiêu trong các phương án sau?
A. O(n^3)
B. O(nlogn)
C. O(n^2)
Câu 117 :
Nếu tương ứng với P1 và P2 là T1(n) = O(f(n)), T2(n) = O(g(n)) thì thời gian thực hiện P1 và P2 lồng nhau sẽ là bao nhiêu trong các phương án sau?
A. T1(n)T2(n) = O(f(n)and g(n))
B. T1(n)T2(n) = O(f(n).g(n))
C. T1(n)T2(n) = O(f(n)+g(n))
Câu 118 :
Thời gian thực hiện các lệnh đơn (gán, đọc, viết) là bao nhiêu trong các phương án sau?
A. O(logn)
B. O(n)
C. O(2)
Câu 119 :
Cho Stack gồm 5 phần tử {12, 5, 20, 23, 72}, trong đó 72 là phần tử ởđỉnh Sta ck. Để lấy ra phần tử thứ 4 trong Stack ta phải thực hiện theo phương án nào?
A. POP(72), POP(23), POP(72)
B. POP(72), POP(23), PUSH(72)
C. POP(23), PUSH(23), POP(72)
Câu 120 :
Trong các giải thuật sắp xếp, giải thuật nào sau đây áp dụng phương pháp Chia để trị?
A. Quick sort, Heap sort
B. Quick sort, Merge sort
C. Quick sort, Bubble sort
Câu 121 :
Hãy cho biết ý tưởng nào sau đây nói về phương pháp sắp xếp nổi bọt (bubble sort)?
A. Phân đoạn dãy thành nhiều dãy con và lần lượt trộn hai dãy con thành dãy lớn hơn, cho đến khi thu được dãy ban đầu đã được sắp xếp
B. Bắt đầu từ cuối dãy đến đầu dãy, ta lần lượt so sánh hai phần tử kế tiếp nhau, nếu phần tử nào nhỏ hơn được đứng vị trí trên
C. Lần lượt lấy phần tử của danh sách chèn vị trí thích hợp của nó trong dãy bằng cách đẩy các phần tử lớn hơn xuống
Câu 122 :
Hãy cho biết ý tưởng nào sau đây nói về phương pháp sắp xếp chọn tăng dần (select sort)?
A. Phân đoạn dãy thành nhiều dãy con và lần lượt trộn hai dãy con thành dãy lớn hơn, cho đến khi thu được dãy ban đầu đã được sắp xếp
B. Lần lượt lấy phần tử của danh sách chèn vị trí thích hợp của nó trong dãy
C. Chọn phần tử bé nhất xếp vào vị trí thứ nhất bằng cách đổi chổ phần tử bé nhất với phần tử thứ nhất; Tương tự đối với phần tử nhỏ thứ hai cho đến phần tử cuối cùng
Câu 123 :
Hãy cho biết ý tưởng nào sau đây nói về phương pháp sắp xếp chèn (insertion sort)?
A. Phân đoạn dãy thành nhiều dãy con và lần lượt trộn hai dãy con thành dãy lớn hơn, cho đến khi thu được dãy ban đầu đã được sắp xếp
B. Lần lượt lấy phần tử của danh sách chèn vị trí thích hợp của nó trong dãy bằng cách đẩy các phần tử lớn hơn xuống
C. Chọn phần tử bé nhất xếp vào vị trí thứ nhất bằng cách đổi chổ phần tử bé nhất với phần tử thứ nhất; Tương tự đối với phần tử nhỏ thứ hai cho đến phần tử cuối cùng
Câu 124 :
Hãy cho biết ý tưởng nào sau đây nói về phương pháp sắp xếp nhanh (Quick sort)?
A. Chọn phần tử bé nhất xếp vào vị trí thứ nhất bằng cách đổi chổ phần tử bé nhất với phần tử thứ nhất; Tương tự đối với phần tử nhỏ thứ hai cho đến phần tử cuối cùng
B. Bắt đầu từ cuối dãy đến đầu dãy, ta lần lượt so sánh hai phần tử kế tiếpnh u, nếu phần tử nào nhỏ hơn được đứng vị trí trên
C. Phân đoạn dãy thành nhiều dãy con và lần lượt trộn hai dãy con thành dãy lớn hơn, cho đến khi thu được dãy ban đầu đã được sắp xếp
Câu 125 :
Phương pháp nào sau đây chính là phương pháp sắp xếp nhanh (Quick sort)?
A. Phương phap trộn
B. Phương pháp vun đống
C. Phương pháp chèn
Câu 126 :
Hãy cho biết ý tưởng nào sau đây nói về tưởng phương pháp sắp xếp Trộn (Merge sort)?
A. Lần lượt chia dãy phần tử thành hai dãy con bởi một phần tử khoá (dãy con trước khoá gồm các phần tử nhỏ hơn khoá và dãy còn lại gồm các phần tử lớn hơn khoá)
B. Bắt đầu từ cuối dãy đến đầu dãy, ta lần lượt so sánh hai phần tử kế tiếp nhau, nếu phần tử nào nhỏ hơn được đứng vị trí trên
C. Chọn phần tử bé nhất xếp vào vị trí thứ nhất bằng cách đổi chổ phần tử bé nhất với phần tử thứ nhất; Tương tự đối với phần tử nhỏ thứ hai cho đến phần tử cuối cùng
Câu 127 :
Hãy cho biết ý tưởng nào sau đây nói về phương pháp sắp xếp vun đống (Heap sort)?
A. Tạo đống cho cây nhị phân (cây nhị phân đã được sắp xếp giảm dần)
B. Lần lượt chia dãy phần tử thành hai dãy con bởi một phần tử khoá (dãy con trước khoá gồm các phần tử nhỏ hơn khoá và dãy còn lại gồm các phần tử lớn hơn khoá)
C. Bắt đầu từ cuối dãy đến đầu dãy, ta lần lượt so sánh hai phần tử kế tiếp nhau, nếu phần tử nào nhỏ hơn được đứng vị trí trên
Câu 128 :
Trong giải thuật sắp xếp vun đống, ta có 4 thủ tục con (Insert - thêm 1 phần tử vào cây; Downheap - vun đống lại sau khi loại một phần tử khỏi Heap, Upheap- vun đống sau khi thêm một phần tử vào cây; Remove - loại 1 phần tử khỏi cây nhị phân). Để sắp xếp các phần tử trong dãy theo phương pháp vun đống, ta thực hiện 4 thủ tục trên theo thứ tự như thế nào sau đây?
A. Remove – Downheap – Insert – Upheap
B. Insert – Upheap – Downheap – Remove
C. Upheap – Downheap – Remove – Insert
Câu 129 :
Hãy cho biết tư tưởng nào sau đây nói về của giải thuật tìm kiếm nhị phân?
A. Lần lượt chia dãy thành hai dãy con dựa vào phần tử khoá, sau đó thực hiện việc tìm kiếm trên hai đoạn đã chia
B. So sánh X lần lượt với các phần tử thứ nhất, thứ hai,... của dãy cho đến khi gặp phần tử có khoá cần tìm
C. Tìm kiếm dựa vào cây nhị tìm kiếm
Câu 130 :
Hãy cho biết tư tưởng nào sau đây nói về của giải thuật tìm kiếm tuần tự?
A. So sánh X lần lượt với các phần tử thứ nhất, thứ hai,... của dãy cho đến khi gặp phần tử có khoá cần tìm
B. Tìm kiếm dựa vào cây nhị tìm kiếm: Nếu giá trị cần tìm nhỏ hơn gốc thì thực hiện tìm kiếm trên cây con trái, ngược lại ta việc tìm kiếm được thực hiện trên cây con phải
C. Lần lượt chia dãy thành hai dãy con dựa vào phần tử khoá, sau đó thực hiện việc tìm kiếm trên hai đoạn đã chia
Câu 131 :
Hãy cho biết tư tưởng nào sau đây nói về của giải thuật tìm kiếm trên cây nhị phân tìm kiếm?
A. Lần lượt chia dãy thành hai dãy con dựa vào phần tử khoá, sau đó thực hiện việc tìm kiếm trên hai đoạn đã chi
B. So sánh X lần lượt với các phần tử thứ nhất, thứ hai,... của dãy cho đến khi gặp phần tử có khoá cần tìm
C. Tìm kiếm dựa vào cây nhị tìm kiếm: Nếu giá trị cần tìm nhỏ hơn gốc thì thực hiện tìm kiếm trên cây con trái, ngược lại ta việc tìm kiếm được thực hiện trên cây con phải
Câu 132 :
Hãy cho biết tính chất nào sau đây là của cây nhị phân tìm kiếm?
A. Cây nhị phân mà mỗi nút trong cây đều thoả tính chất: giá trị của nút cha lớn hơn giá trị của hai nút con
B. Là cây nhị phân đầy đủ
C. Cây nhị phân thoả tính chất heap
Câu 133 :
Cho cây nhị phân: A B C D E F. Cho biết thứ tự các phần tử được duyệt nào sau đây là đúng khi sử dụng phép duyệt cây theo thứ tự trước?
A. A, B, D, C, F, E
B. A, B, C, D, E, F
C. A, B, D, E, C, F
Câu 134 :
Cho cây nhị phân: A B C D E F. Cho biết thứ tự các phần tử được duyệt nào sau đây là đúng khi sử dụng phép duyệt cây theo thứ tự giữa?
A. D, B, E, C, F, A
B. A, B, D, C, E, F
C. D, B, E, F, C, A
Câu 135 :
Cho cây nhị phân: A B C D E F. Cho biết thứ tự các phần tử được duyệt nào sau đây là đúng khi sử dụng phép duyệt cây theo thứ tự sau?
A. A, B, D, C, E, F
B. D, B, E, F, A, C
C. D, B, A, E, C, F
Câu 136 :
Khi lưu trữ cây nhị phân dưới dạng mảng, phần tử ở vị trí số 9 đóng vai trò gì trong các phương án sau?
A. Là nút con phải của nút có vị trí là 4
B. Là nút con trái của nút có vị trí là 5
C. Là nút con trái của nút có vị trí là 4
Câu 137 :
Khi lưu trữ cây nhị phân dưới dạng mảng, nếu vị trí của nút cha là i thì vị trí của nút con trái là gì trong các phương án sau?
A. 2*i + 1
B. i-1
C. 2*i
Câu 138 :
Khi lưu trữ cây nhị phân dưới dạng mảng, nếu vị trí của nút cha trong mảng là i thì vị trí của nút con phải là gì trong các phương án sau?
A. 2*i + 1
B. i+1
C. i-1
Câu 139 :
Trong biểu diễn dữ liệu dưới dạng cây, Khái niệm nào sau đây là cấp của cây?
A. Là tổng số nút trên cây
B. Là cấp cao nhất của nút gố
C. Là cấp cao nhất của một nút trên cây
Câu 140 :
Trong biểu diễn dữ liệu dưới dạng cây, nút có cấp bằng 0 gọi là nút gì trong các phương án sau?
A. Là nút lá
B. Là phần tử cuối cùng trong cây
C. Là nút gố
Câu 141 :
Khi lưu trữ cây nhị phân dưới dạng mảng, nếu vị trí của nút cha trong mảng là 3 thì vị trí tương ứng của nút con phải sẽ bao nhiêu trong các phương án sau?
A. 2
B. 4
C. 6
Câu 142 :
Giải thuật đệ quy là:
A. Trong giải thuật của nó có lời gọi tới chính nó
B. Trong giải thuật của nó có lời gọi tới chính nó nhưng với phạm vi lớn hơn
C. Trong giải thuật của nó có lời gọi tới chính nó nhưng với phạm vi nhỏ hơn
Câu 143 :
Đặc điểm của giải thuật đệ quy:
A. Có một trường hợp đặc biệt, trường hợp suy biến Khi trường hợp này xảy ra thì bài toán còn lại sẽ được giải quyết theo một cách khác
B. Trong thủ tục đệ quy có lời gọi đến chính thủ tục đó
C. Sau mỗi lần có lời gọi đệ quy thì kích thước của bài toán được thu nhỏ hơn trước
Câu 144 :
Danh sách tuyến tính là:
A. Danh sách dạng được lưu dưới dạng mảng
B. Danh sách tuyến tính là một danh sách rỗng
C. Danh sách mà quan hệ lân cận giữa các phần tử được xác định
Câu 145 :
Ưu điểm của việc cài đặt danh sách bằng mảng:
A. Có thể thay đổi số lượng phần tử theo ý muốn của người dùng
B. Có thể bổ sung hoặc xóa một phần tử bất kỳ trong mảng
C. Việc truy nhập vào phần tử của mảng được thực hiện trực tiếp dựa vào địa chỉ tính được (chỉ số), nên tốc độ nhanh và đồng đều đối với mọi phần tử
Câu 146 :
Danh sách tuyến tính dạng ngăn xếp là:
A. Là một danh sách tuyến tính trong đó phép bổ sung sung một phần tử vào ngăn xếp được thực hiện ở một đầu, Và phép loại bỏ không thực hiện được
B. Là một danh sách tuyến tính trong đó phép bổ sung một phần tử vào ngăn xếp được thực hiện ở một đầu , và phép loại bỏ được thực hiện ở đầu kia
C. Là một danh sách tuyến tính trong đó phép bổ sung một phần tử vào ngăn xếp và phép loại bỏ một phần tử khỏi ngăn xếp luôn luôn thực hiện ở tại một vị trí bất kì trong danh sách
Câu 147 :
Định nghĩa danh sách tuyến tính Hàng đợi (Queue):
A. Hàng đợi là kiểu danh sách tuyến tính trong đó, phép bổ sung một phần tử được thực hiện ở một đầu, gọi là lối sau (rear) hay lối trước (front). Phép loại bỏ không thực hiện được
B. Là một danh sách tuyến tính trong đó phép bổ sung một phần tử và phép loại bỏ một phần tử được thực hiện ở tại một vị trí bất kì trong danh sách
C. Hàng đợi là kiểu danh sách tuyến tính trong đó, phép bổ sung phần tử ở một đầu, gọi là lối sau (rear) và phép loại bỏ phần tử được thực hiện ở đầu kia, gọi là lối trước (front)
Câu 148 :
Hàng đợi còn được gọi là danh sách kiểu:
A. LOLO
B. FIFO
C. FILO
Câu 149 :
Cho dãy số {6 1 3 0 5 7 9 2 8 4}. áp dụng phương pháp sắp xếp lựa chọn (Select sort) sau lần lặp đầu tiên của giải thuật ta có kết quả: {0 1 3 6 5 7 9 2 8 4}. Dãy số thu được sau lần lặp thứ hai là:
A. {0 1 2 6 5 7 9 3 8 4}
B. {0 1 3 6 5 7 9 2 8 4}
C. {0 1 2 3 4 5 6 7 8 9}
Câu 150 :
Cho dãy số {6 1 3 0 5 7 9 2 8 4}. áp dụng phương pháp sắp xếp lựa chọn (Select sort) sau lần lặp đầu tiên của giải thuật ta có kết quả: {0 1 3 6 5 7 9 2 8 4}. Dãy số thu được sau lần lặp thứ ba là:
A. {0 1 2 6 5 7 9 3 8 4}
B. {0 1 2 6 5 7 9 3 4 8}
C. {0 1 2 3 6 5 7 9 8 4}
Câu 151 :
Cho dãy số {6 1 3 0 5 7 9 2 8 4}. áp dụng phương pháp sắp xếp lựa chọn (Select sort) sau lần lặp đầu tiên của giải thuật ta có kết quả: {0 1 3 6 5 7 9 2 8 4}. Dãy số thu được sau lần lặp thứ tư là:
A. {0 1 2 3 6 5 7 9 8 4}
B. {0 1 2 3 4 5 6 7 8 9}
C. {0 1 2 3 5 7 9 4 8 6}
Câu 152 :
Cho dãy số {6 1 3 0 5 7 9 2 8 4}. áp dụng phương pháp sắp xếp lựa chọn (Select sort) sau lần lặp đầu tiên của giải thuật ta có kết quả: {0 1 3 6 5 7 9 2 8 4}. Dãy số thu được sau lần lặp thứ năm là:
A. {0 1 2 3 6 5 7 9 8 4}
B. {0 1 2 3 5 7 9 4 8 6}
C. {0 1 2 3 4 5 6 7 8 9}
Câu 153 :
Cho dãy số {6 1 3 0 5 7 9 2 8 4}. áp dụng phương pháp sắp xếp lựa chọn (Select sort) sau lần lặp đầu tiên của giải thuật ta có kết quả: {0 1 3 6 5 7 9 2 8 4}. Dãy số thu được sau lần lặp thứ sáu là:
A. {0 1 2 3 4 7 9 6 8 5}
B. {0 1 2 3 4 5 6 9 8 7}
C. {0 1 2 3 4 5 6 7 8 9}
Câu 154 :
Cho dãy số {3 1 6 0 5 4 8 2 9 7}. áp dụng phương pháp sắp xếp nhanh (Quick sort) sau lần lặp đầu tiên của giải thuật ta có kết quả: {(0 1 2) 3 (5 4 8 6 9 7)}. Dãy số thu được sau lần lặp thứ bốn là:
A. {(0) 1 (2 3) 4 (5 6) 7 (8 9)}
B. {0 1 2 3 (5 4 8 6 9 7)}
C. {(3) 1 (6 0) 5 (4 8) 2 (9 7)}
Câu 155 :
Cho dãy số sau: 40 25 75 15 65 55 90 30 95 85. Áp dụng phương pháp sắp xếp lựa chọn, sau lượt 1 dãy sẽ được sắp xếp lại như thế nào?
A. 15 25 40 75 30 55 65 90 85 95
B. 40 25 75 15 30 65 55 90 85 95
C. 15 25 75 40 65 55 90 30 95 85
Câu 156 :
Cho dãy số sau: 40 25 75 15 65 55 90 30 95 85. Áp dụng phương pháp sắp xếp lựa chọn, sau lượt 2 dãy sẽ được sắp xếp lại như thế nào?
A. 15 25 75 30 40 65 55 90 85 95
B. 15 40 25 75 30 55 65 90 85 95
C. 15 25 75 40 65 55 90 30 95 85
Câu 157 :
Cho dãy số sau: 40 25 75 15 65 55 90 30 95 85. Áp dụng phương pháp sắp xếp hòa nhập (Merge_Sort) trực tiếp, sau lượt 1 dãy sẽ được sắp xếp lại như thế nào?
A. [15 40] [30 25] [55 65] [75 85] [90 95]
B. [40 25] [55 15] [30 65] [75 90] [85 95]
C. [15 25] [40 75] [30 55] [65 90] [85 95]
Câu 158 :
Cho dãy số sau: 14 32 10 43 57 87 55 36 97 11. Áp dụng phương pháp tìm kiếm tuần tự, sau bao nhiều lần thực hiện phép so sánh ta sẽ tìm thấy số 43?
A. 2 lần
B. 3 lần
C. 4 lần
Câu 159 :
Cho dãy số sau: 10 11 14 32 36 43 55 57 87 97 . Áp dụng phương pháp tìm kiếm nhị phân, sau bao nhiêu lần phân đoạn ta sẽ tìm thấy số 43?
A. 2 lần
B. 3 lần
C. 4 lần
Câu 160 :
Cho dãy số sau: 10 11 14 32 36 43 55 57 87 97. Áp dụng phương pháp tìm kiếm nhị phân, để tìm kiếm số 10, lần phân đoạn thứ nhất của dãy sẽ là:
A. [14 32 10 43 57]
B. [10 11 14 32 36]
C. [87 55 36 97 11]
Câu 161 :
Cho dãy số sau: 10 11 14 32 36 43 55 57 87 97. Áp dụng phương pháp tìm kiếm nhị phân, để tìm kiếm số 97, lần phân đoạn thứ hai của dãy sẽ là:
A. [36 97]
B. [36 11]
C. [36 97 11]
Câu 162 :
Tính chất nào sau đây là tính chất của cây nhị phân tìm kiếm:
A. Mọi khóa thuộc cây con trái nút đó đều nhỏ hơn khóa ứng với nút đó
B. Mọi khóa thuộc cây con trái nút đó đều lớn hơn khóa ứng với nút đó
C. Mọi khóa thuộc cây con trái nút đó đều lớn hơn khóa cây con phải nút đó
Câu 163 :
Các thuộc tính của một kiểu dữ liệu?
A. Tên kiểu dữ liệu
B. Tập các toán tử tác động lên kiểu dữ liệu
C. Kích thước lưu trữ
Câu 164 :
Miền giá trị của Kiểu số nguyên là:
A. -32767 .. 32768
B. 0..32768
C. -32768 .. 32767
Câu 165 :
Tập các toán tử kiểu số nguyên là:
A. +, -, , /, %, các phép so sánh, div ,mod
B. +, -, , /, %, các phép so sánh
Câu 166 :
Chọn câu trả lời đúng nhất về thuật toán?
A. Thuật toán là một dãy hữu hạn các bước, tất cả các phép toán có mặt trong các bước của thuật toán phải đủ đơn giản
B. Thuật toán là nòng cốt của chương trình
C. Thuật toán là một dãy hữu hạn các bước, mỗi bước mô tả chính xác các phép toán hoặc hành động cần thực hiện để giải quyết vấn đề đặt ra
Câu 167 :
Đặc trưng nào của thuật toán thể hiện: Tất cả các phép toán có mặt trong các bước của thuật toán phải đủ đơn giản:
A. Tính xác định
B. Tính khả thi
Câu 168 :
Để viết chương trình chỉ để sử dụng một số ít lần và cái giá của thời gian viết chương trình vượt xa cái giá của chạy chương trình thì ta chọn thuật toán:
A. Thuật toán sử dụng tiếp kiện nhất nguồn tài nguyên của máy tính, và đặc biệt, chạy nhanh nhất có thể được
B. Thuật toán đơn giản, dễ hiểu, dễ cài đặt (dễ viết chương trình)
Câu 169 :
Khi viết các chương trình (thủ tục hoặc hàm) để sử dụng nhiều lần, cho nhiều người sử dụng ta chọn thuật toán:
A. Thuật toán sử dụng tiếp kiện nhất nguồn tài nguyên của máy tính, và đặc biệt, chạy nhanh nhất có thể được
B. Thuật toán đơn giản, dễ hiểu, dễ cài đặt (dễ viết chương trình)
Câu 170 :
Cài đặt danh sách bằng con trỏ có nghĩa là
A. Dùng con trỏ để liên kết các phần tử của danh sách theo phương thức ai chỉ đến ai+1. Để một phần tử có thể chỉ đến một phần tử khác ta xem mỗi ô là một Record gồm có 2 trường : Trường Elements để giữ nội dung
của phần tử trong danh sách. Trường Next là một con trỏ giữ địa chỉ của ô kế tiếp
B. Dùng một mảng (array) để lưu trữ liên tiếp các phần tử của danh sách bắt đầu từ vị trí đầu tiên của mảng. Khai báo bản ghi gồm 2 trường:Trường Elements để giữ nội dung của phần tử trong danh sách. Trường Next là
một con trỏ giữ địa chỉ của ô kế tiếp
C. Dùng con trỏ quản lí các phần tử của mảng theo phương thức bất kì. Để một phần tử có thể chỉ đến một phần tử khác ta xem mỗi ô là một Record gồm có 2 trường : Trường Elements để giữ nội dung của phần tử trong
danh sách. Trường Next là một con trỏ giữ địa chỉ của ô kế tiếp.
Câu 171 :
Đối với biến con trỏ Hàm MaxAvail: Longint: có nghĩa là gì?
A. Cho biết số bytes được cấp phát / thu hồi bởi biến
B. Hàm cho biết tổng số bytes còn lại trên Heap
C. Hàm cho biết vùng nhớ lớn nhất còn trống trong Heap
Câu 172 :
Đối với biến con trỏ Hàm MemAvail: Longint : có nghĩa là gì?
A. Cho biết số bytes được cấp phát / thu hồi bởi biến
B. Hàm cho biết vùng nhớ lớn nhất được cấp phát
C. Hàm cho biết tổng số bytes còn lại trên Heap
Câu 173 :
Đối với biến con trỏ Hàm SizeOf (Biến ): Longint: có nghĩa là gì?
A. Cho biết số bytes được cấp phát / thu hồi bởi biến
B. Hàm cho biết vùng nhớ lớn nhất được cấp phát
C. Hàm cho biết vùng nhớ lớn nhất còn trống trong Heap.
Câu 174 :
Đối với biến con trỏ hàm Add (x): Pointer có chức năng gì?
A. Cho biết địa chỉ segment của biến x
B. Cho biết địa chỉ seg: Ofs
C. Cho biết địa chỉ Offset của biến x
Câu 175 :
Đối với biến con trỏ hàm Seg (x): Word có chức năng gì?
A. Cho biết địa chỉ segment của biến x
B. Cho biết địa chỉ Offset của biến x
C. Cho biết địa chỉ seg: Ofs
Câu 176 :
Đối với biến con trỏ hàm Ofs (x): Word có chức năng gì?
A. Cho biết địa chỉ seg: Ofs
B. Cho biết địa chỉ segment của biến x
C. Cho biết địa chỉ tổng quát của biến x
Câu 177 :
Thế nào là sắp xếp trong?
A. Sắp xếp trong là sắp xếp dữ liệu không cần đến bộ nhớ trong máy tính, mà chỉ cần các đối tượng được lưu trũ bằng bộ nhớ ngoài
B. Sắp xếp trong là sự sắp xếp được sử dụng khi số lượng đối tượng được sắp xếp lớn. Cụ thể là ta sẽ sắp xếp dữ liệu được lưu trữ trong các tập tin
C. Sắp xếp trong là sắp xếp không phụ thuộc vào độ dài tập tin. Mà chỉ phụ thuộc vào bộ nhớ trong của máy tính
Câu 178 :
Thế nào là sắp xếp ngoài?
A. Sắp xếp ngoài là sự sắp xếp được sử dụng khi số lượng đối tượng được sắp xếp lớn. Cụ thể là ta sẽ sắp xếp dữ liệu được lưu trữ trong các tập tin
B. Sắp xếp ngoài là sắp xếp không phụ thuộc vào độ dài tập tin. Mà chỉ phụ thuộc vào bộ nhớ trong của máy tính
C. Sắp xếp ngoài là sự sắp xếp dữ liệu được tổ chức trong bộ nhớ trong cuả máy tính, ở đó ta có thể sử dụng khả năng truy nhập ngẫu nhiên của bộ nhớ
Câu 179 :
Đâu là phương pháp sắp xếp trong, trong các phương pháp sau:
A. Phương pháp nổi bọt(Bubble sort)
B. Phương pháp sắp xếp chèn (selection sort)
C. Phương pháp sắp xếp chọn (insertion sort)
Câu 180 :
Đâu là phương pháp sắp xếp ngoài, trong các phương pháp sau:
A. Phương pháp sắp xếp chèn (insertion sort)
B. Phương pháp sắp xếp chọn (selection sort)
C. Phương pháp nổi bọt(Bubble sort)
Câu 181 :
Thế nào là ngôn ngữ giả?
A. Ngôn ngữ giả là cấu trúc của môt chuương trình chỉ viết bằng ngôn ngữ Pascal mà tuỳ thuộc vào nguười lập trình
B. Ngôn ngữ giả là ngôn ngữ do ngưuoi lập trình định nghĩa
C. Ngôn ngữ giả là sự kết hợp của ngôn ngữ tự nhiên và các cấu trúc của một ngôn ngữ lập trình nào đó
Câu 182 :
Bước tổng quát của Phương pháp sắp xếp kiểu chèn (insertion sort):
A. Chọn phần tử có khoá nhỏ nhất trong n-i+1 phần tử từ a[i] đến a[n] và hoán vị nó với a[i]
B. Xen phần tử a[i+1] vào danh sách đã có thứ tự a[1],a[2],..a[i] sao cho a[1], a[2],.. a[i+1] là một danh sách có thứ tự
Câu 183 :
Thời gian chạy chương trình phụ thuộc vào các yếu tố nào?
A. Dữ liệu đầu vào
B. Tôc độ của máy được dùng
C. Tính chất của trình biên dich được dùng
Câu 184 :
Nếu T1(n) và T2(n) là thời gian chạy của 2 đoạn chương trình P1 ,P2. Thời gian chạy của hai chuơng trình P1, P2 nối nhau là:
A. T=T1-T2
B. T = T1 T2
C. T=T1/T2
Câu 185 :
Nếu T1(n) và T2(n) là thời gian chạy của 2 đoạn chương trình P1 ,P2. Thời gian chạy của hai chuơng trình P1, P2 lồng nhau là:
A. T=T1*T2
B. T=T1/T2
C. T=T1+T2
Câu 186 :
Thời gian chạy của các lệnh gán, Read, Write là:
A. O(2)
B. O(1)
C. O(n)
Câu 187 :
Thời gian chạy của một chuỗi tuần tự áp dụng quy tắc:
A. Quy tắc Trừ
B. Quy tắc Cộng
C. Quy tắc Nhân
Câu 188 :
Cho lệnh gán X := F với F = 5X + 7Y , X=6, Y =X + 2. Sau lệnh này X có giá trị:
A. 53
B. 71
C. 72
Câu 189 :
Cho lệnh gán X := F với F = arctg(x) , x = Pi / 4 . Sau lệnh gán này X có giá trị:
A. 1
B. 2
C. 3
Câu 190 :
Cho điều kiện if B then ( y = 7x + 3 ) else ( y = x^2 + 1 ), B là điều kiện x> 7. Khi x=7 thì y có giá trị là:
A. 47
B. 50
C. 51
Câu 191 :
Cho lệnh lặp: for i:=1 to 4 do y=3i + 6 . Hãy xác định các kết quả thu được:
A. 9,12,15,18
B. 3,6,9,12
C. 7,10,13,16
Câu 192 :
Cho lệnh While B do x^2 + 7, trong đó B là x>3. Khi kiểm tra điều kiện B thì thấy x=3. Kết quả của lệnh này là:
A. =7
B. =15
C. =16
Câu 193 :
Trong giải thuật xếp 8 con hậu, nếu đã có con hậu ở ô (5,3) thì không con hậu nào được nằm ở ô:
A. (2,4)
B. (4,5)
C. (7,5)
Câu 194 :
Trong giải thuật xếp 8 con hậu, nếu có con hậu ở ô (4,5) thì không con hậu nào được ở ô:
A. (1,8)
B. (2,3)
C. (3,7)
Câu 195 :
Trên 1 bàn cờ, những ô nằm trên cùng một đường chéo từ dưói lên với ô (i,j) có hệ thức:
A. (hàng - cột)=i+j
B. (hàng - côt)=i-j
C. (hàng + cột)=i-j
Câu 196 :
Trong số các phép toán sau đây, phép toán nào không được dùng đối với mảng:
A. Lưu trữ mảng
B. Tạo mảng
C. Tìm kiếm trên mảng
Câu 197 :
Cho mảng một chiều A=(a1,a2,…,ax,…,an) và được lưu trữ liên tiếp. Giả thử mỗi phần tử của mảng chiếm 3 ô và phần tử đầu tiên F(1) có địa chỉ 23 thì phần tử F(4) có địa chỉ:
A. 15
B. 41
C. 52
Câu 198 :
Cho mảng 2 chiều : A={F( i j)} i là chỉ số hàng, j là chỉ số cột. Mảng A có 8 hàng, 9 cột. Lưu trữ liên tiếp mảng A ưu tiên hàng. Nếu phần tử F(11) có địa chỉ 50, mỗi phần tử chiếm 3 ô thì phần tử F(57) có địa chỉ:
A. 148
B. 152
C. 162
Câu 199 :
Cho mảng 2 chiều A={F( i j)}: i là chỉ số hàng, j là chỉ số cột. Mảng A có 8 hàng, 9 cột. Lưu trữ liên tiếp mảng A ưu tiên cột nếu phần tử F(11) có địa chỉ 230 , mỗi phần tử chiếm 3 ô thì phần tử F(37) có địa chỉ:
A. 378
B. 382
C. 380
Câu 200 :
Dùng phương pháp lưu trữ liên tiếp để lưu trữ một ma trận ( mảng hai chiều) có nhược điểm lớn nhất là:
A. Cần một lượng ô nhớ lớn
B. Lãng phí ô nhớ khi ma trận thưa
Câu 201 :
Dùng STACK để lưu trữ số nhị phân có giá trị bằng số thập phân 215 ta có kết quả: (số bên trái vào trước số bên phải)
A. 11001110
B. 11101011
C. 10111101
Câu 202 :
Cho cây nhị phân T. Phép duyệt thứ tự trước cho kết quả là:
A. ADBCEFG
B. AEBDCGF
C. AEDBCFG
Câu 203 :
Độ cao của cây là gì?
A. Cấp lớn nhất của nút
B. Số cây con của cây
C. Số lượng nút của cây
Câu 204 :
Cho cây nhị phân T, nút có địa chỉ 7 có 2 con ở địa chỉ nào:
A. 8 và 9
B. 13 và 14
C. 14 và 15
Câu 205 :
Cây 5 phân có nghĩa là gì?
A. Mức có nhiều nút nhất là 5
B. Cây có chiều cao là 5
C. Nút có cấp lớn nhất là 5
Câu 206 :
Có 6 tầu x1,x2,x3,x4,x5,x6. Gọi V là lệnh đưa 1 đầu tầu vào kho ( kho là 1 STACK), R là lệnh đưa 1 đầu tầu từ kho ra để sửa: Vởy ta phải thực hiện các lệnh V, R theo thứ tự nào để ta sẽ sửa chữa lần lượt 3 đầu tầu: x3, x2, x4:
A. V(1) V(2) R(2) R(1) V(3) V(4) R(4)
B. V(1) R(1) V(2) R(2) V(3) V(4) R(4)
C. V(1) V(2) V(3) V(4) R(4) R(3) R(2)
Câu 207 :
Cho dãy khoá 42,23,74,11,65,58 . Dùng phương pháp sắp xếp kiểu chọn (selection sort), sau 3 bước dãy có dạng nào?
A. 11,23,74,58,65,42
B. 42,11,74,23,58,65
C. 11,23,42,74,58,65
Câu 208 :
Ý tưởng phương pháp sắp xếp nổi bọt (bubble sort) là:
A. Phân đoạn dãy thành nhiều dãy con và lần lượt trộn hai dãy con thành dãy lớn hơn, cho đến khi thu được dãy ban đầu đã được sắp xếp
B. Chọn phần tử bé nhất xếp vào vị trí thứ nhất bằng cách đổi chổ phần tử bé nhất với phần tử thứ nhấ; Tương tự đối với phần tử nhỏ thứ hai,ba...
C. Bắt đầu từ cuối dãy đến đầu dãy, ta lần lượt so sánh hai phần tử kế tiếp nhau, nếu phần tử nào nhỏ hơn được đứng vị trí trên
Câu 209 :
Phương pháp sắp xếp nhanh (Quick sort) chính là phương pháp:
A. Trộn
B. Phân đoạn
C. Vun đống
Câu 210 :
Cơ chế heap trong sắp xếp vun đống là:
A. Cây nhị phân đầy đủ với tính chất giá trị của nút cha luôn lớn hơn giá trị hai nút con
B. Cây nhị phân hoàn chỉnh với tính chất giá trị của nút cha lớn luôn lớn hơn giá trị các nút trong cây con trái và nhỏ hơn giá trị các nút trong cây con phải
C. Cây nhị phân hoàn chỉnh với tính chất giá trị của nút cha luôn lớn hơn giá trị hai nút con
Câu 211 :
Trong giải thuật sắp xếp vun đống, ta có 4 thủ tục con (Insert - thêm 1 phần tử vào cây; Downheap - vun đống lại sau khi loại một phần tử khỏi Heap, Upheap- vun đống sau khi thêm một phần tử vào cây; Remove - loại 1 phần tử khỏi cây nhị phân). Để sắp xếp các phần tử trong dãy theo phương pháp vun đống, ta thực hiện 4 thủ tục trên theo thứ tự như thế nào?
A. Remove – Downheap – Insert – Upheap
B. Insert – Upheap – Downheap – Remove
C. Upheap – Downheap – Remove – Insert
Câu 212 :
Tư tưởng của giải thuật tìm kiếm tuần tự
A. So sánh X lần lượt với các phần tử thứ nhất, thứ hai,... của dãy cho đến khi gặp phần tử có khoá cần tìm
Câu 213 :
Tư tưởng của giải thuật tìm kiếm nhị phân:
A. Tìm kiếm dựa vào cây nhị tìm kiếm
B. Lần lượt chia dãy thành hai dãy con dựa vào phần tử khoá, sau đó thực hiện việc tìm kiếm trên hai đoạn đã chia
C. Tại mỗi bước tiến hành so sánh X với phần tử ở giữa của dãy,Dựa vào bước so sánh này quyết định giới hạn dãy tìm kiếm nằm ở nửa trên, hay nửa dưới của dãy hiện hành
Câu 214 :
Giả sử có hàm tính số Fibonaci là fibo(int n), cho biết lệnh nào đúng khi tính giá trị Fibonaci của n và gán cho biến kết quả?
A. kq==fibo(n);
B. kq!=fibo(n);
C. kq=fibo(n)
Câu 215 :
Bài toán tháp Hà Nội được phát biểu như sau: Input: có 3 cái cọc và n cái đĩa xếp tại cọc 1 Output: Chỉ ra các bước thực hiện di chuyển n cái đĩa từ cọc 1 sang cọc. Nếu sử dụng giải thuật đệ quy, chỉ ra trường hợp gọi đệ quy:
A. n > 0
B. n > 1
C. n > 2
Câu 216 :
Để dịch chuyển các đĩa từ cọc B sang cọc C với cọc A là trung gian, lệnh gọi hàm nào là đúng?
A. dichuyen(n,"A","C","B");
B. dichuyen(n,"A","B","C");
C. dichuyen(n,"A","B","C")
Lời giải có ở chi tiết câu hỏi nhé! (click chuột vào câu hỏi).
Copyright © 2021 HOCTAP247